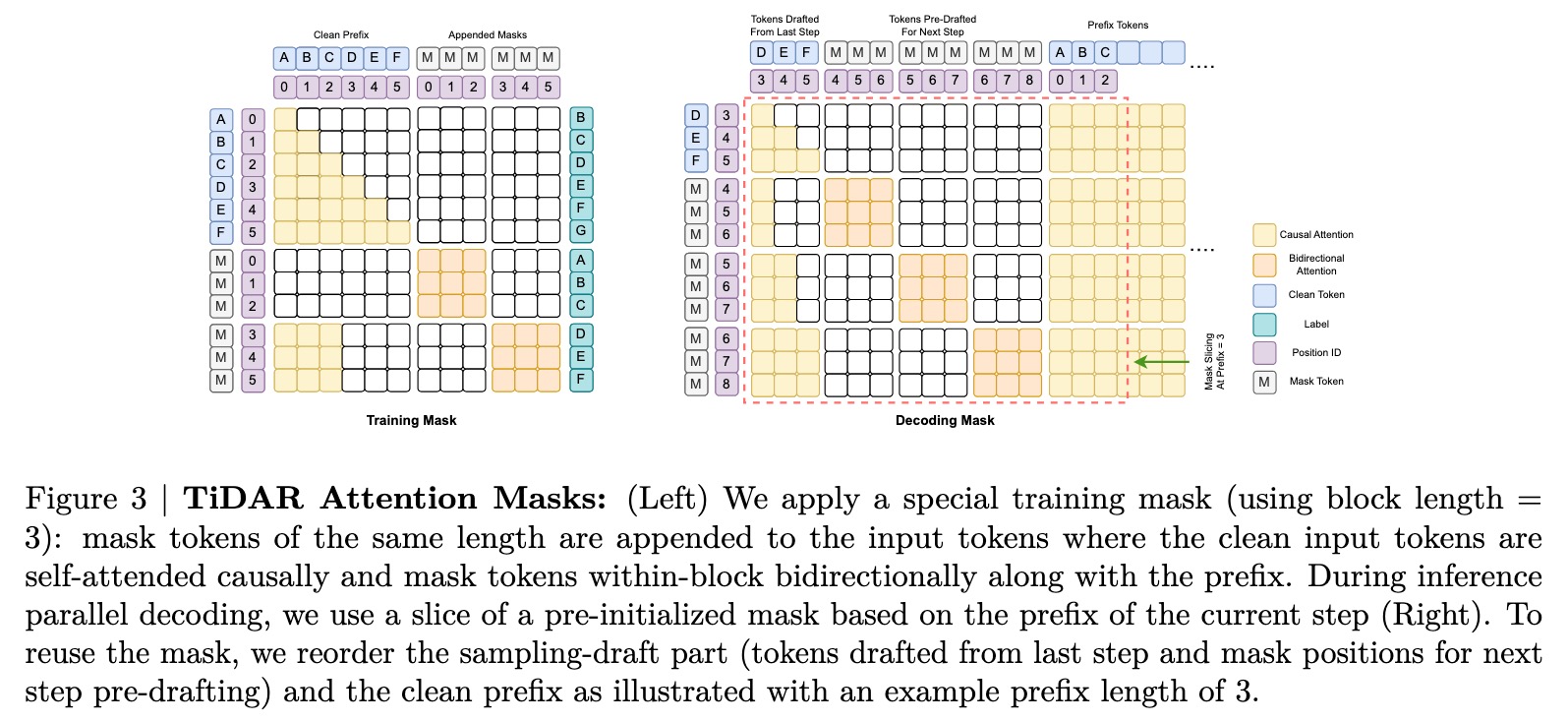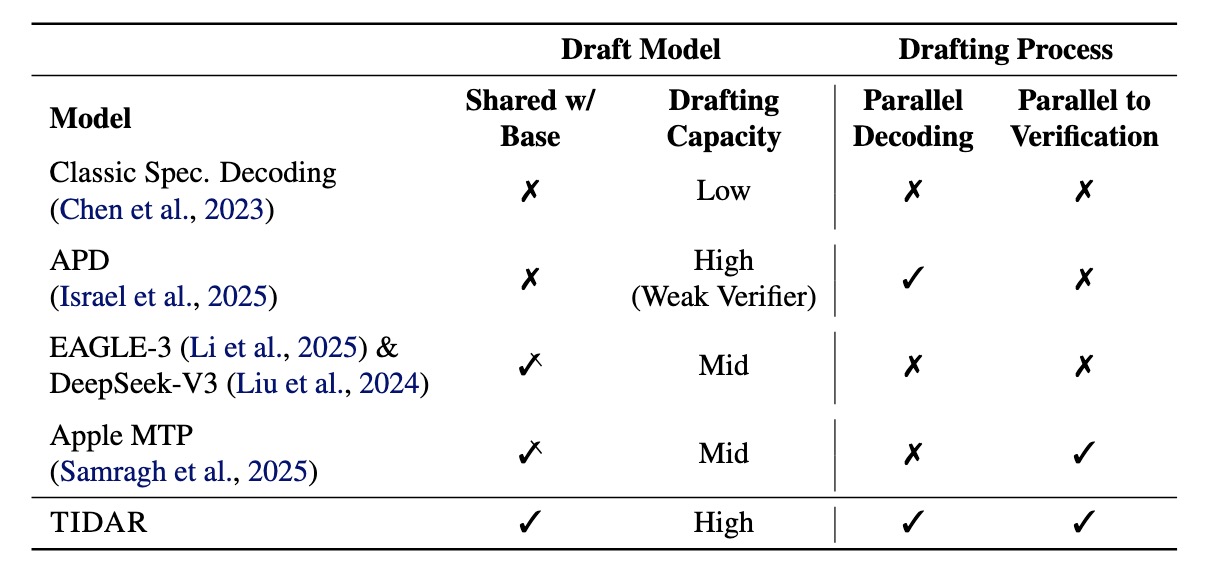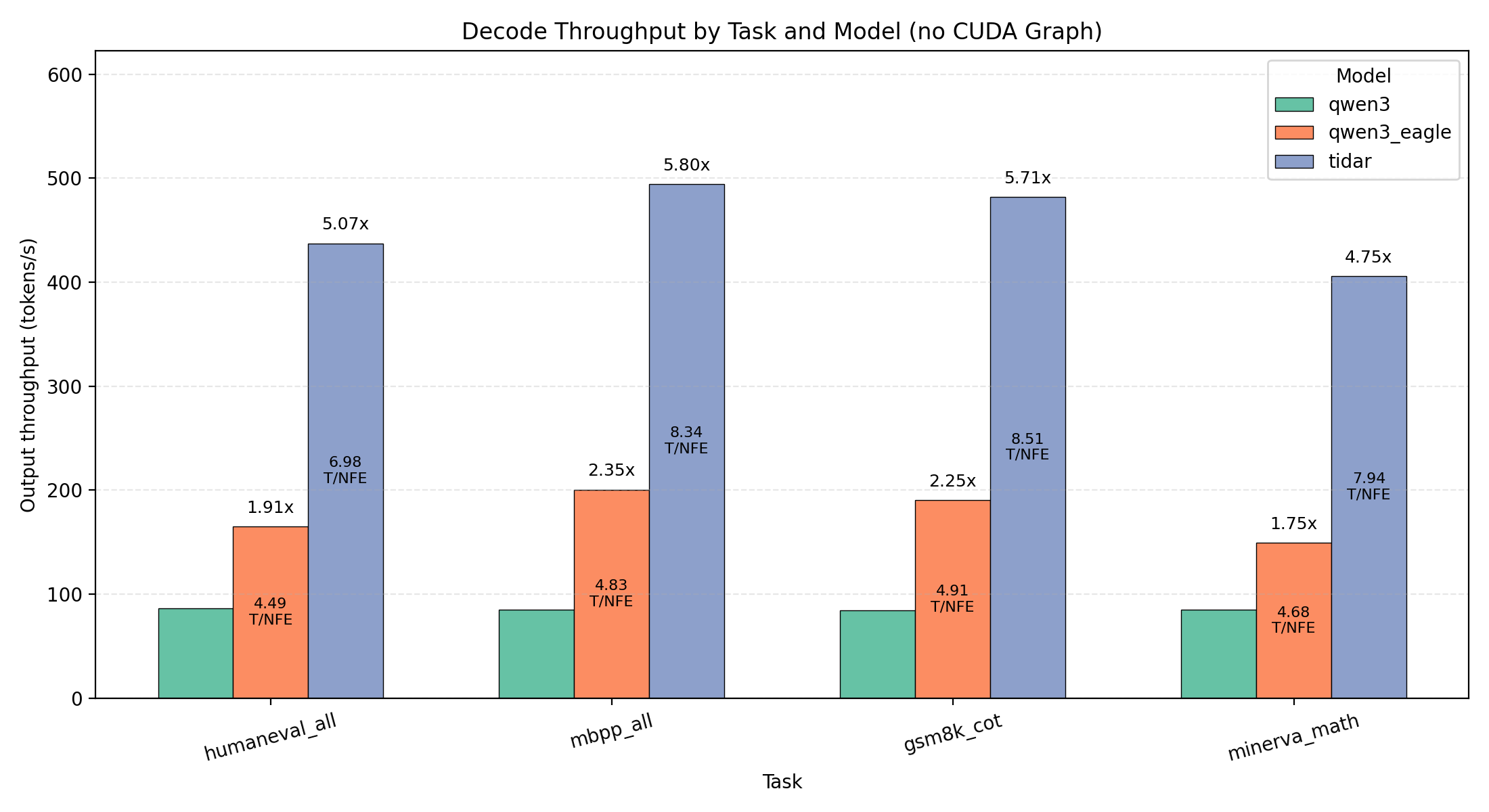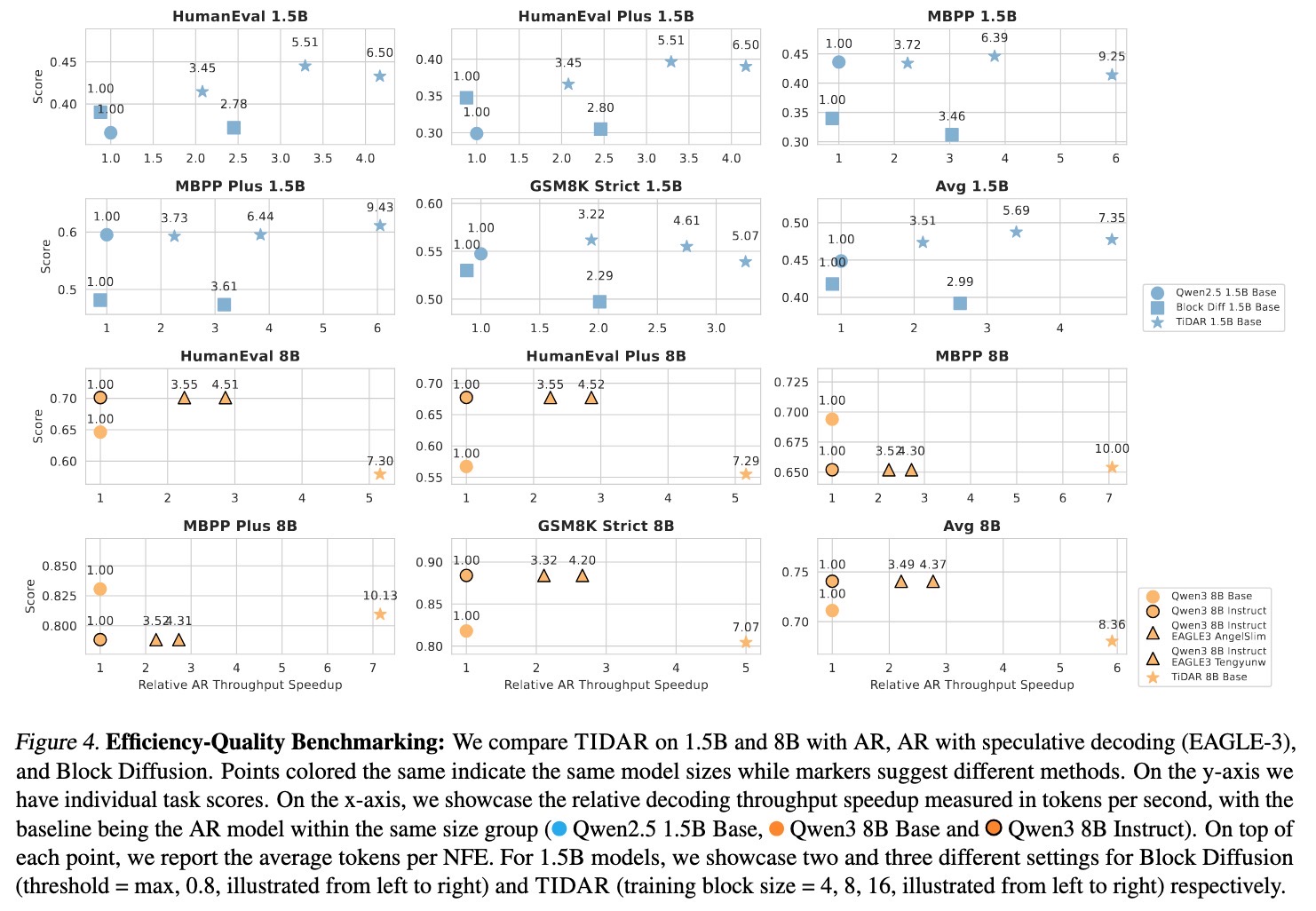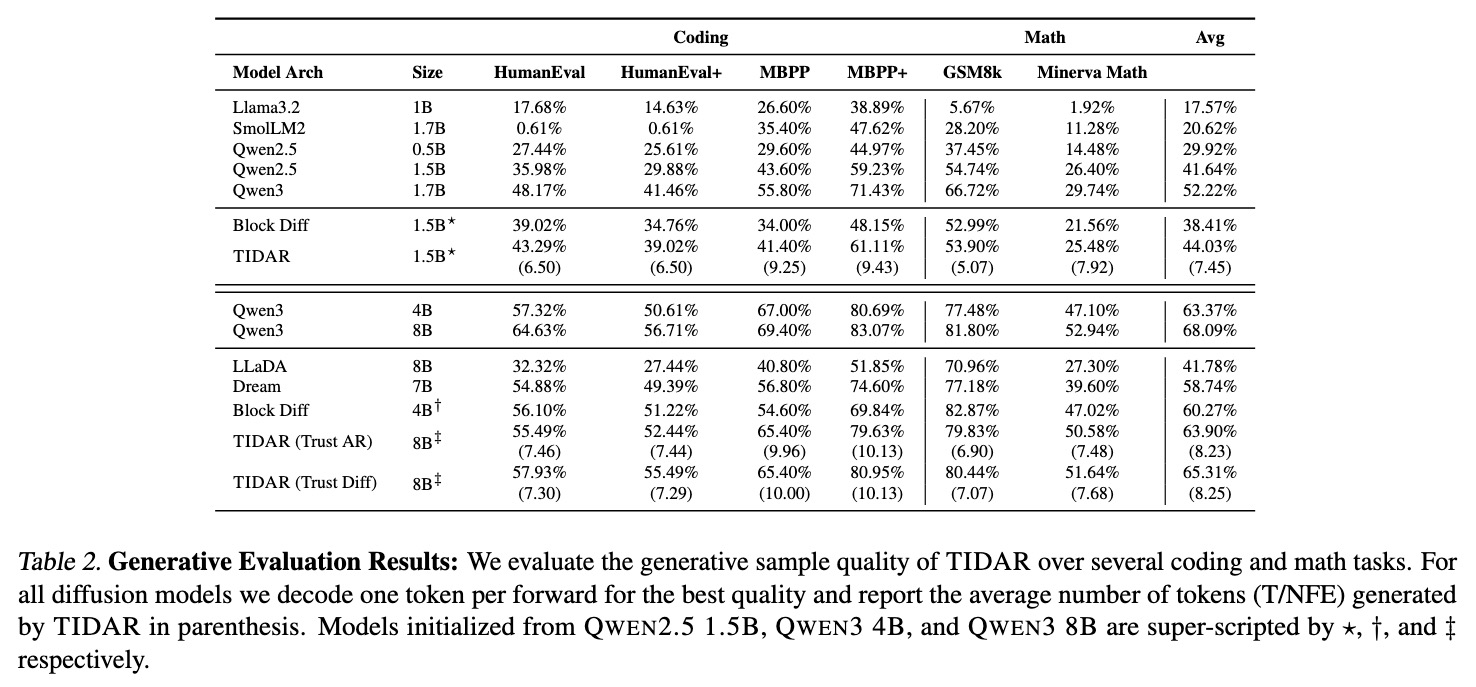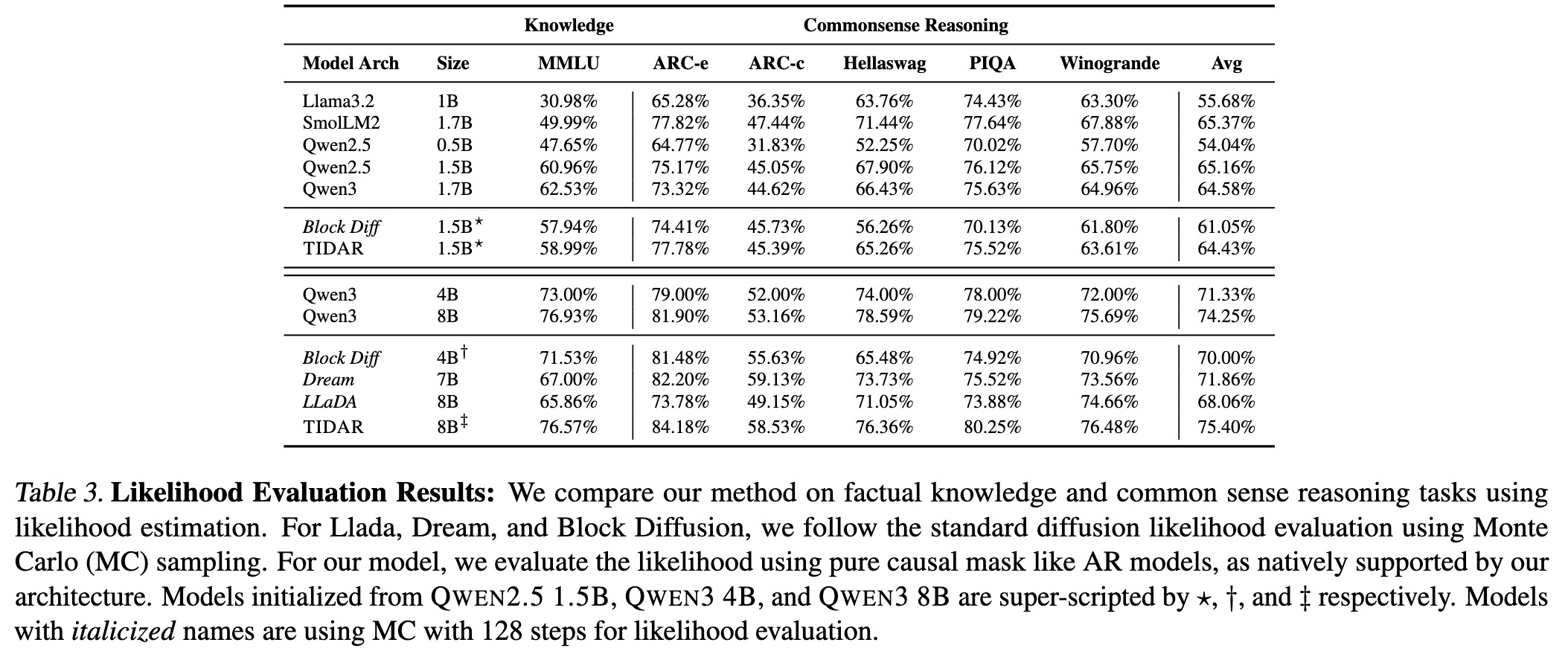
The Secret Sauce: Free Token Slots
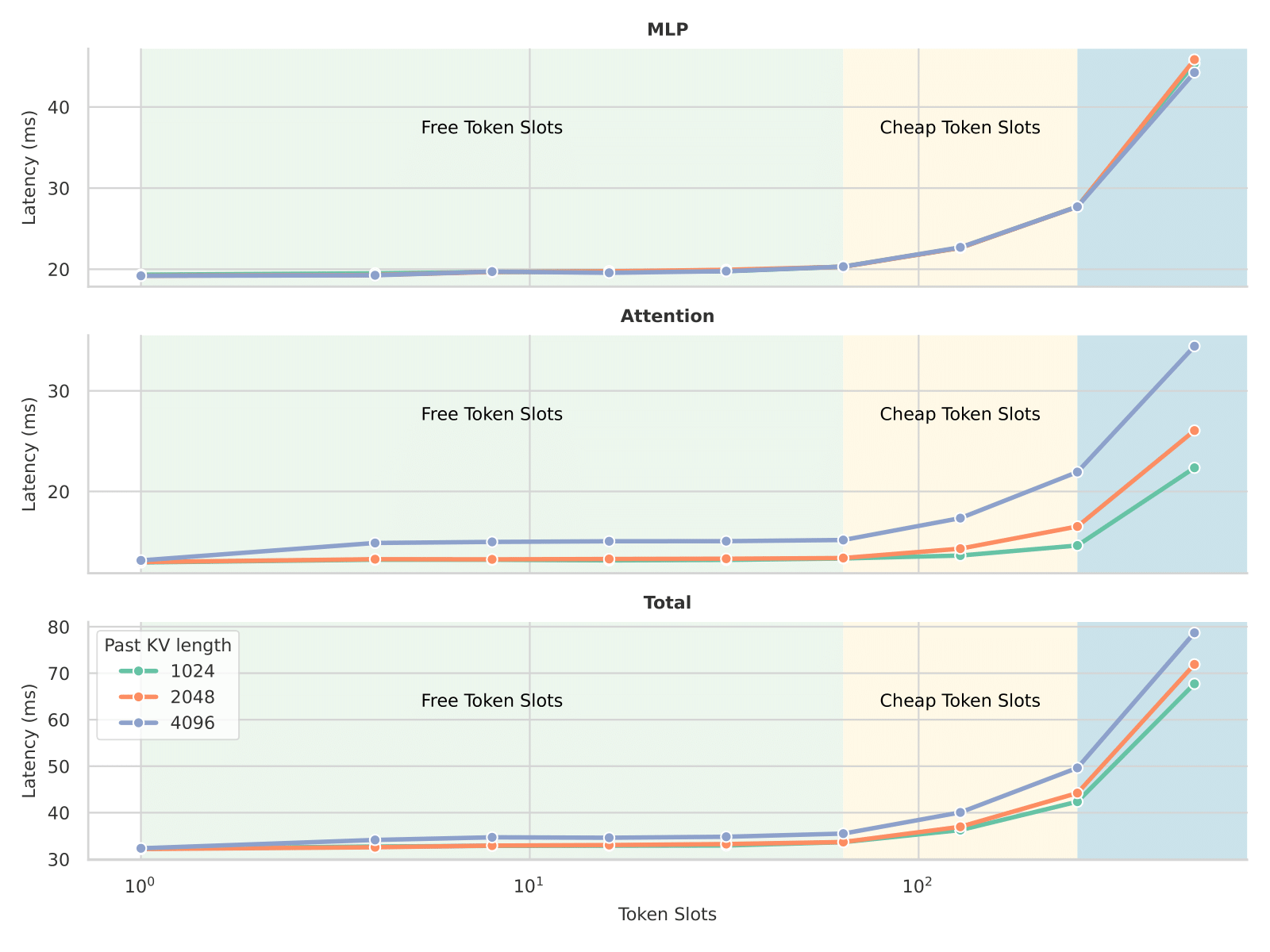
The power of modern GPUs gets fully utilized under a balanced load between compute density and memory IO. Increasing batch size can increase the compute density by reusing the model weights, but this requires loading more KV cache for each sample and more aggressive model sharding. It turns out that passing a decent amount of extra tokens to the forward results in similar latency. Under the context of TiDAR, we append sets of mask tokens to perform diffusion pre-drafting and also verifiying tokens from last step to conduct autoregressive sampling. When the draft length is chosen wisely, computing these extra tokens in parallel does not introduce extra latency, and therefore, we refer to these as "free token slots".